
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 논문리뷰
- Apache
- aws
- word2vec
- 가비아
- Selenium
- Lamp
- 한빛아카데미
- jupyter
- 딥러닝
- AndroidStudio를활용한안드로이드프로그래밍
- 한빛미디어
- 소스설치
- deeplearning
- 머신러닝
- MySQL
- 생활코딩
- 밑바닥부터시작하는딥러닝
- 밑바닥부터시작하는딥러닝2
- 수동설치
- 비지도학습
- 프로그램새내기를위한자바언어프로그래밍
- image
- 셀레니움
- attention
- Crawling
- CBOW
- 크롤링
- 컴파일설치
- 예제중심HTML&자바스크립트&CSS
Archives
- Today
- Total
안녕, 세상!
RSANet: Towards Real-Time Object Detection with Residual Semantic-Guided Attention Feature Pyramid Network 본문
It공부/딥러닝논문리뷰
RSANet: Towards Real-Time Object Detection with Residual Semantic-Guided Attention Feature Pyramid Network
dev_Lumin 2022. 3. 26. 09:47Abstract
- 규모가 큰 컴퓨팅 overhead는 object detection을 위한 mobile devices에서의 convolutional neural networks의 inference를 제한시킴
- 이를 해결하기 위해서 해당 논문은 RSANet이라고 부르는 경량화 convolutional neural network를 제안함
- 크게 두 가지 파트로 나뉨
- (a) Lightweight Convolutional Network (LCNet) as backbone
- (b) Residual Semantic-gudied Attention Feature Pyramid Network (RSAFPN) as detection head
- LCNet
- Feature maps의 수를 변경하기 위해 point-wise convolution을 사용하는 것을 선호하는 최신 진보된 경령화 기법과 다르게 설계
- Constant Channel Module (CCM)을 설계하여 Memory Access Cost를 줄이고,
- Down Sampling Module*을 설계하여 computational cost를 줄임
- RSAPFN
- Detection 성능을 효과적으로 개선하기 위해서,
- LCNet*으로 부터의 multi-scale features를 fuse하는 Residual Semantic-guided Attention Mechanism (RSAM)을 이용함
- 실험 결과는
- PASCAL VOC 20007 dataset 기반으로
- RSANet은 오직 3.24M model size가 요구되고
416x416 input image에 대하여 3.54B FLOPs가 필요함 - YOLO Nano와 비교해서
- 더 적은 computation으로 6.7% 정확도 향상
- RSANet은 오직 3.24M model size가 요구되고
- MS COCO dataset 기반으로
- RSANet은 4.35M model size가 요구되고
320x320 input image에 대해서 2.34B FLOPs가 필요함 - Pelee와 비교해서
- 1.3%의 정확도 향상
- RSANet은 4.35M model size가 요구되고
- PASCAL VOC 20007 dataset 기반으로
- 모델은 Speed와 accuracy trade-off관점에서 유망한 결과를 보여줌
1. Introduction
- CNN은 computer vision에서 지배적이고,
높은 정확도를 얻기 위해 더 깊어지고 넓어지는것이 일반적임 - 이러한 이점으로 최근에 deep CNNs를 사용한 object detection task에서 눈에 띄는 성과와 개선이 이뤄짐
- 특히 region-based 접근이 detection accuracy를 크게 향상 시킴
- 하지만 extra region proposal extraction step 때문에, two-stage 방식은 real-time application 시나리오에서 computational 비용이 큼
- 이를 대안으로 one-stage pipline을 다룰려고 시도함
- Class probabilitie와 bounding box offsets가 forward convolutional network를 이용하여 full image로부터 feature maps에서 바로 예측됨
- 이로 인해 one-stage는 extra region proposal extraction step이 필요 없음
- Pipe-line이 하나이기에 time-saving 하고 더 real-time applcation에서 수용 가능함
- 하지만 이 방식들은 오직 pipeline의 단순화에만 집중을 하고 network 그 자체로서의 complexity는 무시함
- 이러한 문제들을 해결하, real-time 시나리오를 채택하기 위해서,
효율적인 CNN models를 memory와 computational budgets의 엄격한 조건에서 실행될 수 있도록 한 연구들이 많아짐 - Network inference 속도를 빠르게 하는 요인들은 다음과 같음
- Model size
- Computational cost
- MAC
- 이를 해결하기 위한 연구들에도 한계가 존재함
- 그들은 오직 model size와 computational cost만 고려했지,
inference 시간에 대한 MAC 효과를 무시함
- 그들은 오직 model size와 computational cost만 고려했지,
- 그리하여 본 논문은 제한된 computational cost 조건에서 MAC를 최소화시키기 위한 CCM을 사용함
- 또한 RSAM을 채택하여 더 강력한 feature representation을 얻고자 함
- 더 구체적으로 말하자면,
- RSANet*이라는 새로운 real-time network를 설계하고,
정확도와 효율성의 trade-off를 달성하기 위한 효율적인 RSAFPN을 채택함
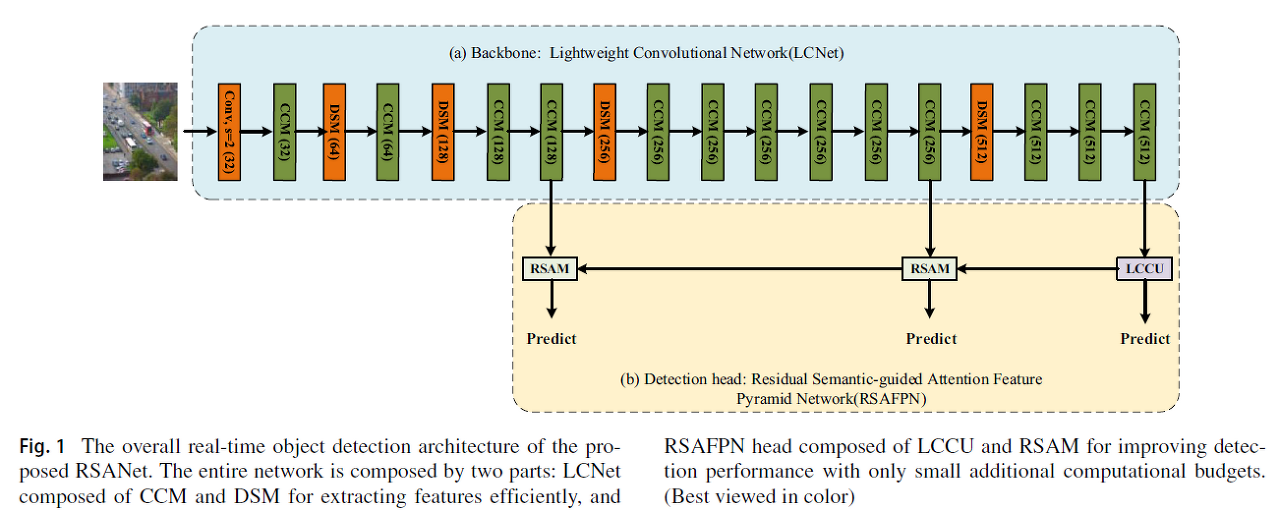
- Fig 1에서 볼 수 있듯이,
RSANet은 크게 두가지 파트로 나뉨- (a) LCNet as backbone
- (b) RSAFPN as detection head
- ShuffleNetv2로 부터 영감을 받아서, backbone network는 주로 CCM으로 구성됨
- 전체 Block 모두 feature map channels수가 일정함
- → 이것은 MAC를 최소화시키는것을 목적으로 함
- Stride 2를 가진 표준적인 convolution에 반하여,
논문의 DSM은 stride 2를 가진 depthwise convolution과 max pooling을 섞어서
computational cost를 아낌 - Low-level features (초반 단계)는 localization에 대한 local detail 정보를 포함하고 있고,
High-level features (후반단계)는 classification을 위한 global semantic information을 가지고 있음- Semantic information
- Not only what objects are present in an image but, perhaps even more importantly, the relationship between those obeject
- Semantic information
- 대부분의 object detection 연구는 FPN (Feature Pyramid Network) framework을 채택하여,
addtion 또는 concatenation operation을 사용하여 high-level features와 low-level features를 결합시킴

(위의 그림은 Feature Pyramid Network를 나타내는 그림)
- 이런 방식으로라면, 모든 levels에서 풍부한 semantics를 가진 feature pyramid는 하나의 input image scale로부터 구축됨
- RSAFPN framework에서 FPN기반 RSAM을 소개하고,
이는 high-level features로부터 강력한 semantic 정보가 정확한 classification을 위해 low-level features를 guide(안내)하는 데 사용됨 - 반면에, RSAFPN은 적은 computational overhead 환경에서 context information을 잡아내기 위해서 depthwise convolution을 사용하는 LCCU 유닛을 이용함
- 요약하자면 contribution은 다음과 같음
- 새로운 CCM을 제안하여 MAC를 최소화시킴
- CCM과 DSM기반으로, features을 추출하는 LCNet이라는 이름의 backbone network를 앞에 배치시킴 ( put forward)
- Computational cost를 줄이기 위해서 LCCU를 사용한 RSAFPN head를 설계함
또한 적은 추가적 computational budgets으로 detection 정확도 향상을 달성하기 위해서, - RSAFPN*으로 embedded 되는 RSAM을 제안함
그로인해 LCNet과 RSAPFN으로 구성된 전체 네트워크는 경량화됨 - 실험 결과는 RSANet이 speed와 accuracy 사이의 available trade-off 관점의 object detection에서 유망하게 성능을 낸다는 것을 보임
2. Related work
Real-time object detection
- 최근에 object detection piplines 기반 딥러닝은 크게 두 개의 categories로 나뉨
- (1) two-stage detectors
- e.g. R-CNN
- (2) One-stage detectors
- e.g. YOLO
- (1) two-stage detectors
- Two-stage detectors가 주로 public benchmarks에서 더 나은 성능을 보이는 반면,
One-stage detectors는 제안된 computational resources에서 object를 detect 하는데 더 적합함 - Depth separable convolution
- Standard convolution과 다름
- Standard convolution에서 convolution kernel가 모든 input channels를 필터링함
- 먼저 서로 다른 input channels를 개별적으로 convolve 하는 depthwise convolution을 진행 후,
depth seperable convolution의 outputs를 linearly 하게 합치는 pointwise convolution을 사용함
- Standard convolution과 다름
- 최근 연구들은 depth seperable convolution이 standard convolution과 비교해서 비슷하거나 심지어 더 좋은 결과들을 성취할 수 있으며,
동시에 computational resources를 매우 절약해주고 model size도 거의 사용지 않는다고 함 - 이러한 depth seperable convolution을 사용한 여러 연구들은 object detection을 위한 경량화에 사용되어서 많은 기여를 했지만,
중요한 요소인 MAC을 무시하고 진행함 - 이러한 방식과 다르게 본 논문에서는 inference speed에서의 MAC효과를 고려한 LCNet이라는 이름을 가진 lightweight backbone을 디자인함
Vision attention
- Speech recogntion의 application에 많은 영감을 받아서, visual attention은 computer vision community에서 많이 쓰임
- Attention mechanism은 성능을 향상하기 위해 feed forward network를 guide 하는 global context로 사용될 수 있음
- 최근 몇 년간, large-scale classification tasks에서 CNNs의 성능을 향상하기 위해서 attention processing을 통합하는 몇몇 시도들이 이뤄짐
- 대표적으로 Squeeze-and-Excitation module은 channel-wise attention을 compute 하는 global average-pooled features를 사용함
- 이러한 models와 다르게, 본 논문에서는 RSAM을 사용함
- 이러한 attention 관련 연구들은 vision attention 영역에서 많은 발전을 이뤘지만, 그들은 reweighting을 위한 각 detection layer에서 오직 attention map만 만들었고, 더 얕은 layer classification로 향하는 더 깊은 layer의 semantic information의 중요성을 무시함 (?)
- 해당 연구에서는 RSAFPN을 구축하는데 필요한 RSAM에서 FPN구조까지 소개함
- 이 RSAFPN은 low level detection performance를 향상시키기 위한 강력한 semantic informationd을 제공하는 high-level features를 encoding 함
3. Method
- 연구진들은 accuracy와 computational complexity를 둘 다 중요하게 생각함
3.1 Network architecture
- 연구의 주 동기는 accuracy와 efficiency 사이의 가장 좋은 가능한 trade-off을 성취하는 network를 얻는 것임
- 크게 두 구조인 LCNet과 SPAFPN 가 있음
- LCNet은 적은 computational overhead조건에서도 strong 구조를 디자인할 수 있도록 하는 CCM 기반으로 설계됨
- Detection 부분에서는 SAFPN을 채택함으로써 high-level semantic 정보와 low-level detail 정보를 융합하여 detection performance를 효과적으로 향상시킴
3.2 LCNet
- LCNet은 VGG와 같은 plain overall 구조를 따름

- Backbone의 핵심은 CCM과 DSM으로 Fig 2d에서 개별적으로 묘사되어 있음
- LCNet은 총 5 stages로 구성됨
- Fisrt stage
- 3x3 standard convolution with stride 2
- The rest stages
- 논문의 DSM으로 시작됨
- Fisrt stage
- 각 stage에서 CCM의 수는 각각
1, 1, 2, 6, 3 - 마지막 3 stages로부터의 feature maps는 multi-scale detection을 위해 사용됨
- 각 모듈에서 bracket에서의 수는 convolutional kernels의 수를 나타냄을 숙지하셈
3.2.1 CCM
- 최근 몇 년 간 많은 효율적인 residual modules가 소개되어 왔음
- e.g. residual bottleneck, inverted residual bottleneck and PEP
- 하지만 이러한 방식들은 각 convolutional layer의 output feature channels의 수가 input feature channels의 수와 다르며,
이는 곧 MAC의 증가를 초래함 - 반면에 CCM은 input과 output features 사이의 channels의 수의 일정함을 유지하며, 이는 MAC를 절약하게 되고 inference process의 속도를 빠르게 해 줌
- CCM은 Depthwise Convolution의 강력함과 residual connections가 결합됨
- 구체적으로 Fig. 2d에 묘사되어 있음

-
- 3x3 filter kernel은 각 channel마다 input을 convolved 시키고, output channels에 응답하여 독립적인 filtering 결과를 초래함
- 그 후, 1x1 pointwise convolution이 channels의 linear combinations를 학습함으로써 channel dependency를 회복하는 데 사용됨
- 그리고 이 두 동작들은 각 CCM에서 한 번 더 수행됨
- Channels의 수가 모두 달랐던 이전 연구에 반하여,
feature map chanels의 수가 CCM에서의 모든 block에서 일정하게 유지함 - CCM의 효과는 ablation study section에서 설명함
- (이 논문은 object detection에 초점이 맞춰져 있지만, 연구진들은 visual tasks 관련 다른 존재하는 network 구조로 쉽게 전이되어 사용될 수 있다고 믿고 있음)
3.2.2 DSM
- Downsampling의 동작은 CNN구조에서 흔하게 사용됨
- Downsampling의 주 단점은 feature 해상도(resolution)의 감소이지만,
또한 두 가지의 이점이 존재함- 깊은 layers가 classification을 향상하는 context를 더 모을 수 있도록 함
- Computation을 줄일 수 있음
- 이에 따라, impalement 효율성과 detection performance 사이의 좋은 균형을 유지하기 위해서, LCNet은 5 downsampling operations를 채택함
- 대부분의 연구들은 여분의 computational budgets 없이 해상도를 줄이기 위해서 max-pooling layer 또는 stride 2를 가진 convolution을 채택했지만,
그들의 관계를 고려하지 않고 filtered 된 responses를 바로 버림 - 반면에, stride convolution은 pixel의 관계들을 점차 학습하면서 feature의 해상도를 줄일 수 있지만, 추가적인 computational cost가 발생함
- 논문의 DSM은 stride 2를 가진 DWC와 max-pooling을 결합하여, 두 함수의 이점을 수용함

- Fig. 2e에서 설명되어 있듯이 DSM은 두 개의 branches로 구성되어 있음
- Left branches는 stride 2를 가진 3x3 DWC를 채택함
- Right branches는 max-pooling을 사용하여 실행됨
- 이후 1x1 convolution은 2개의 branches의 outputs를 linearly 하게 결합하는데 사용됨
3.3 RSAFPN

- Fig. 1b에 보이듯이, RSAFPN detection head을 구축하는 데 사용되는 RSAM을 소개함
- RSAM은 정확한 detection을 위한 low-level features를 guide(안내)하는 high-level features로부터의 semantic 정보를 이용함
- Low-level features는 local detail information을 가지고,
high-level features는 classification을 위한 global semantic 정보를 담고 있음 - 이에 따라, low-level features를 reweight 하기 위해서 high-level features로부터의 semantics으로 channel attention을 추상화시킴
- 반면에 FPN framework은 high-level features와 low-level features를 융합하는 mainstream 방법임
- 그러므로, 제안한 RSAM을 FPN으로 소개함
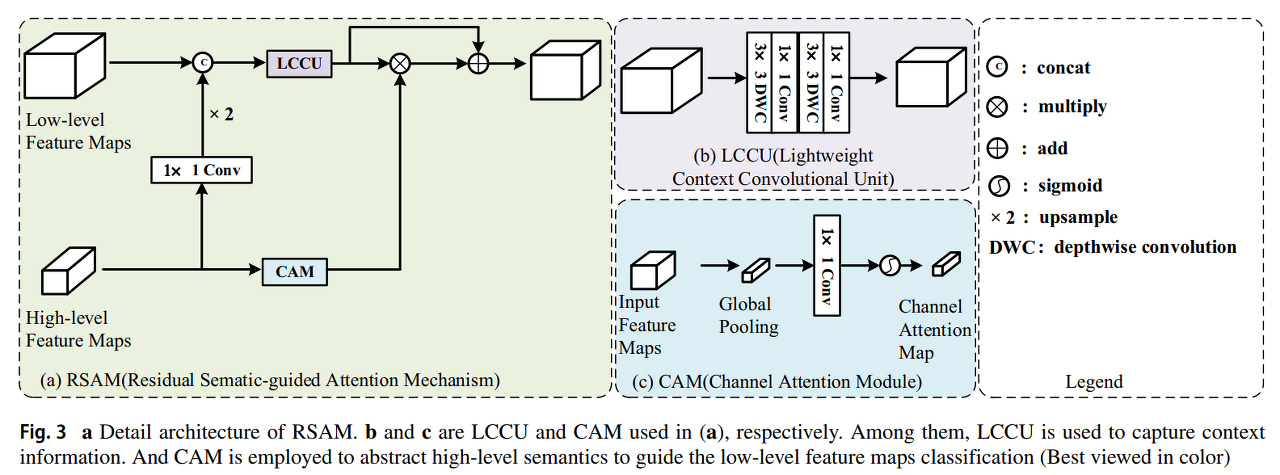
- Fig. 3a에 묘사되어있듯이, 처음에 feature channels를 줄이는 pointwise convolution을 사용함
- High-level features의 수가 low-level features의 수보다 두 배 더 많기에
- 반면에, pointwise convolution의 outputs를 2번 upsample 하여, low-level features의 해상도에 매칭 시킴
- LCCU는 high-level과 low-level features의 concatenation을 기반으로 context 정보를 잡아내기 위해서 채택됨
- 이후, CAM은 global attention을 사용하여 high-level semantics를 추상화시키는 데 사용됨
- 마지막으로 semantic information은 LCCU의 output이 reweighted feature maps를 생성하도록 guide 하는 데 사용됨
- 구체적으로는 CAN에 의해 영감을 받아, LCCU는 inference 속도를 향상하도록 computational cost를 절약하도록 설계됨
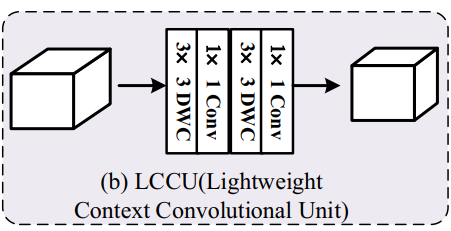
- Fig. 3b에 보이듯이 LCCU에서 두 개의 3x3 depthwise convolution을 채택하여 context 정보를 잡아내도록 함
- 첫 번째 1x1 convolution은 channels reduction을 위해서 사용되고,
두 번 째 1x1은 depthwise convolution의 output을 섞기 위해서 사용됨
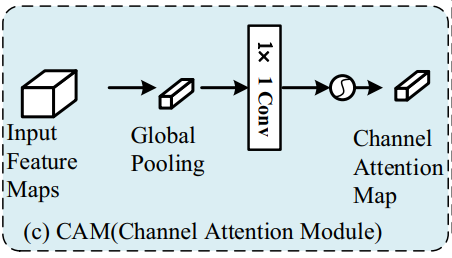
- Fig. 3c에서 보이듯이 CAM은 low-level feature maps가 high-level feature로부터 semantic information을 얻도록 도와줌
- 첫째로, 강력한 semantic information을 생성하기 위해서 high-level features에 global average pooling을 이용함
- 이후, 1x1 convolution은 LCCU output의 feature 차원에 맞춰주기 위해서 dimension reduction을 위해서 사용됨
- 이후 1x1 convolution의 output을 normalization 하기 위해 sigmoid function을 사용함
- 마지막으로 abstract attention vector은 LCCU의 output을 reweigh 하기 위해 사용됨
4. Experiments
- method의 효율성을 증명하기 위해서 두 개의 자주 사용되는 일반적인 object detection datasets인 PASCAL VOC 2007과 MS COCO를 사용함
- 논문에서 제안한 CCM의 이점을 말하기 위해서 두 개의 ablation studies를 진행하였고, 제안한 RSAM으로부터 성능 향상을 보임
- Sota와 비교하였을 때 제안한 모델이 accuracy와 efficiency trade-off의 관점에서 두 데이터셋에서 우월한 성능을 성취함
4.1 Implementation details
Dataset
- PASCAL VOC 2007
- 20 object classs
- 이미지의 해상도는 약 500x375 그리고 375x500 임
- MS COCO
- 80 object classes
Hyper-parameters settings
- RSANet는 Tensorflow library로 구현됨
- GeForce RTX 2080ti GPU 환경에서 학습됨
- Adam optimizer
- 320x320 input size에 24 mini-batch 혹은
416x416 input size에 12 images - Learning rate : warm up to 1e-3 for first epoch
- cosine scheduler를 따라서 나머지 iterations에 대해 1e-6만큼 줄임
- 이렇게 한것은 연구진들이 시작부터 너무 갑자기 learning rate를 감소시키고 싶지 않았고, 마지막에서는 매우 작은 learning rate를 사용하여 해상도를 “refine” 시키고 싶어서 그런것임
- → Traingin stable intially하게 만들기 위해서
- Computational resource의 제한을 위해서, imagenet dataset으로 pretrain된 model에 의존하지 않음
- 즉, scratch부터 network를 학습시킴으로써, 어떤 제한 없이 전체 network의 모든 layer을 정제(refine)함
Evaluation metrics
- 실행 효율성을 측정하기 위해서 Computational cost는 FLOPs로, model size는 parameter의 수로 평가하는 동시에,
detection accuracy를 모든 class에 대해서 평가하기 위해서 mAP를 사용함
4.2 Evaluation on Pascal VOC 2007


- 4.3 Evaluation on MS COCO


4.4 Ablation study
4.1 Ablation study for CCM design
- FLOPs를 일정하게 유지하면서 ratio의 best setting를 찾아내기 위해서 다음과 같은 실험을 함
- ShuffleNetv2에 영감을 받아, 연구진들은 dot convolution의 input과 output channels의 일정함을 유지하는것이 memory access와 inference의 속도를 향상시킨다는것을 증명함
- Backbone인 LCNet을 구성하는 CCM모듈을 사용하고 pointwise convolution feature map의 point convolution의 input과 output channels의 비율을 변경함
- 이와중에 FLOPs의 일정함은 유지함

- 첫 번 째 열
- 고정된 computational costs에서 backbone의 각 convolution layer의 다른 channel 수를 나타냄
- 결과적으로 일정하게 유지하는것이 FPS가 높음
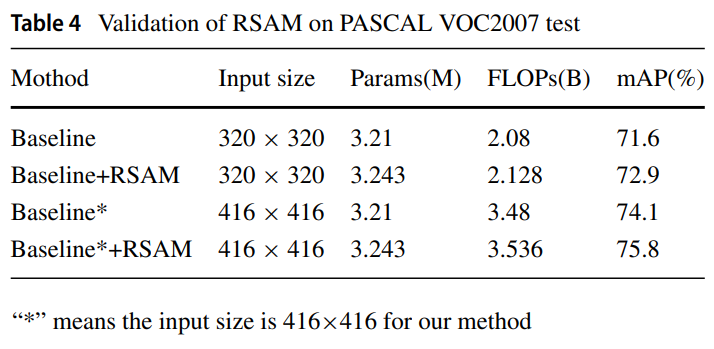
4.4.2 Ablation study for RSAM
- RSAM의 효과를 증며하기 위해서, Pascal VOC 2007로 실험을 함
- RSAFPN안에 RSAM을 추가함으로써 attention의 효과를 증명함
5. Conclusion
- RSANet은 lightweight network backbone과 강력한 multi-scale feature fusion head를 개발하는데 중점을 두고, accuracy와 efficiency 사이의 trade-off을 성취함
'It공부 > 딥러닝논문리뷰' 카테고리의 다른 글
'It공부/딥러닝논문리뷰' Related Articles
more




Comments